- 정보검색 방법 개요
Term Frequency : tf
단어 빈도수는 말 그대로 "단어가 그 문서에서 나타난 횟수"를 나타낸다.

Document Frequency : df
문서 빈도수는 "해당 단어가 나타난 문서의 수" 이다. 따라서 각 단어가 그 문서에서 얼마나 나타났는지는 중요하지 않고, 몇개의 문서에서 나타났는지가 중요하다. 이 정보는, 만약 df 값이 높은 단어는 많은 문서에서 나타나는 것이므로, 검색에서 별로 중요한 단어가 아니라는 것을 나타낸다. (검색에 중요한 단어는 내가 찾을 문서에선 많이 나타나고, 다른 문서에선 적게 나타날 수록 중요하다.)
Inverse Document Frequency : idf
역문서 빈도수는 df를 역수 취한 것이다. df는 값이 클 수록 중요하지 않은 단어를 나타내는 것인데, 이것을 반대로 값이 클수록 중요한 단어로 나타내기 위하여 역수를 취한다고 보면 된다. 또한, df의 값의 범위는 굉장이 넓게 구성되는데, 이것의 차를 줄이기 위하여 로그(log) 값을 취해 준다.

tf-idf Weight
tf-idf는 단어의 중요도를 수치로 표현 한 것으로써, tf 값과 idf값의 곱으로 이루어 진다.

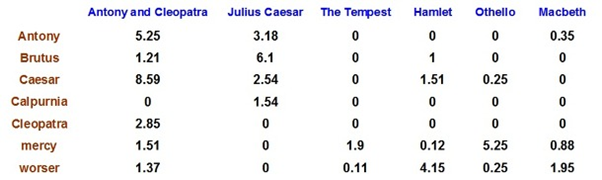
Cosine Similarity : cos(q,d)
각도를 고려한 유사도 계산법을 알아보자.
벡터 스페이스 모델에서 가장 많이 사용되는 문서와 질의어 간의 유사도 계산법이 바로, 코사인 유사도 방법이다.
- 객체 설계도 및 구현 상세 내용
IndexWordDB : 일단 IndexWordDB에 대해서 설명 하자면 모든 문서에서 글자를 두 글자씩 따서 예를 들면 안녕하세요가 있으면 안녕, 녕하, 하세, 세요 이렇게 스트링을 따와서 KEY 값에 넣고 Data의 값으로는 다 0으로 넣어 뒀다. 이로서 모든 문서의 두글자를 다 저장해놨다.
WordDfDB : 이 DB는 각 색인어의 Df값 즉 그 단어가 전체 문서중 몇 개의 문서에 나오나를 저장해놨다. 이때 IndexWordDB를 사용하였다.
docDB[1] ~ docDB[30] : 이것이 이 프로젝트의 핵심 DB다 30개의 총 문서에 하나하나씩 DB를 주었으면 각 DB에는 그문서의 id,title,size를 저장 하였으며 제일 중요한 tf-idf를 저장하였다. 특히 tf-idf를 저장할때는 맨처음에는 tf를 저장해놓았가 WordDfDB에 저장되어 있는 Df를 이용해 tf-idf 가중치로 그값을 변환하였다.
Cos 클래스 : 이 클래스에다가는 docNum(문서번호), similarity(코사인유사도)를 저장하였다. 특히 Comparable<Cos>인터페이스를 구현하여 sort함수를 써 similarity가 큰 순으로 정렬 하였다.
- 실행 결과



깃허브
https://github.com/icd0422/Information-Retrieval-Engine
icd0422/Search-Engine
Contribute to icd0422/Search-Engine development by creating an account on GitHub.
github.com